
I have created a dataset called “Employee”, it is specialized into 2 subclasses (“Teacher” and “Seller”).
Let’s suppose i generate 20 Employee, in which way i can reference the first 10 tuples of employee with the dataset type created in Teacher and the last 10 tuples in Seller?
You will need a row of __id with Row Number and a named Formula row
The formula will be :-
if field(’__id’)<=10 then
from_dataset(“Teacher”, “column”, join_criteria)
else
from_dataset(“Seller”, “column”, join_criteria)
end
I think join to the dataset is from_dataset("Teacher", "column", id: __id) but not sure
Thanks for the reply, i tried to put a field (type row number) in People called “r”.
Then in the schema Teacher i’ve put the id_teacher (type dataset) and an hidden field called “__row”.
In the formula for picking the id_teacher from the id of People i inserted:
from_dataset(“People”, “id_people”, __row : r) but as you can see it says that can not find the field
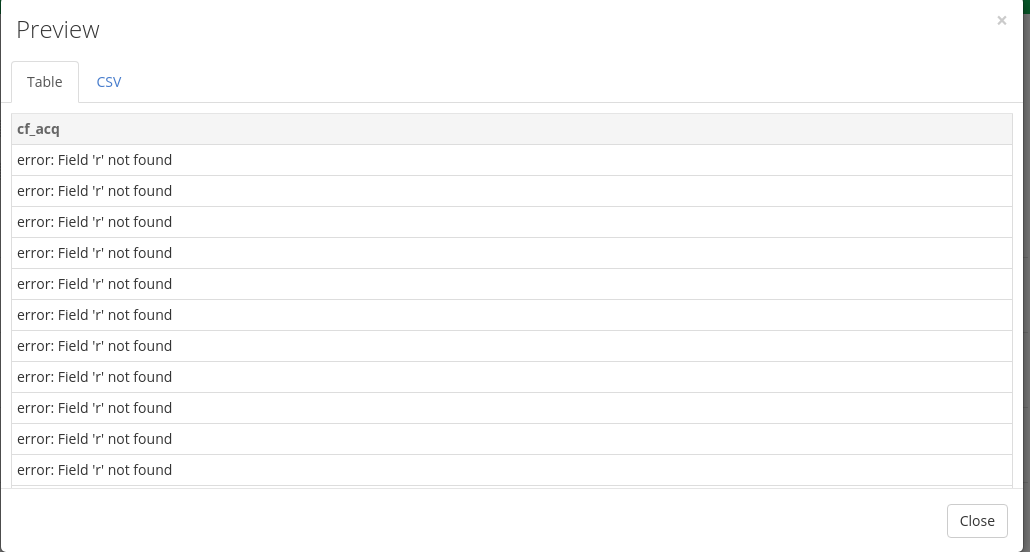
It looks like you have the criteria the wrong way round
I have done the below
if field(’___row’)<=10 then from_dataset(“Teacher”, “first_name”, id_teacher: ___row) else from_dataset(“Seller”, “first_name”, id_seller: __row) end
also do not have dataset column name the same as the schema name (e.g. id: id) I think it confuses the app.
And the seller must have rows starting from 10 but the below will start from the 1st row in the seller
if field(’___row’)<=10 then from_dataset(“Teacher”, “first_name”, id_teacher: ___row) else from_dataset(“Seller”, “first_name”, id_seller: (__row - 10)) end
Solved, i just want to include a link to another related topic where other users can find extra exemples
1 Like